Richard Gayle
Mathematics
Black Hills State University, S.D.
Some four and a half years ago an article by Professor Paul Trout of the English Department at MSU-Bozeman entitled What Students Want: A Meditation on Course Evaluations appeared in the Montana Professor concerning what might be gleaned from the comments solicited of students on student evaluations of faculty about their attitudes toward education. The hilarity induced by some of the extracted students' comments was sufficient justification for the article, but at a more sober level, it provided a context, namely the nearly insatiable societal demand in this country that we collectively and individually be entertained, in which to view the students' comments on an evaluation form and the form itself. My purpose here is similar. I want to suggest another paradigm and another context within which to consider student evaluations of teaching and the increasing emphasis which they receive when faculty at institutions of all levels come under review for promotion or tenure. Unlike Professor Trout's article, however, I proceed from an examination of the statistics of student evaluations of teaching rather than from a semantic parsing of the comments offered by students.
Such an approach is warranted on at least two grounds. When student evaluations of teaching are used as a criterion in deciding on the worthiness of faculty for retention and promotion, invariably it is the quantitative aspects of the form which receive attention, albeit, as we will see shortly, generally remarkably naive attention. Thus, an examination of the end use to which these evaluation instruments are put entails quantitative considerations. Beyond that, though, a quantitative examination opens an avenue to understanding a useful context, that of consumerism, in which to view the meaning and use of these instruments.
Before pursuing a careful analysis of data taken from teaching evaluations, a short detour is in order to consider the bogus analysis to which such data are regularly subjected. The appended evaluation form, currently in use at Black Hills State University (BHSU), provides a reasonable point of departure for this discussion. The form consists of thirteen questions through which the student evaluates a course and the instructor of that course followed by four questions (one of which is worded so poorly as to be worthless) which provide rather unreliable demographic information concerning the student. (The unreliability of this demographic data is born out by the fact that the estimated average self-reported grade point average taken from student evaluations in the fall semester of 2000 is one half of a letter grade higher than the known average GPA for all students that semester.) Each evaluative question is, in fact, a statement to which the student is asked to react with strong agreement (1), agreement (2), neutrality (3), disagreement (4), or strong disagreement (5). The statement wording ensures that agreement is in each case a response favorable to the instructor, disagreement unfavorable. A reading of the statement/questions reveals, as one might expect in this situation, that the majority of the items call for the students to make subjective judgements in absence of any definite guiding criteria. It could hardly be otherwise; a form such as this is, de facto, an instrument for gathering opinion as opposed to establishing a quantitative assessment of objective reality. The thing that should draw one's immediate attention here is that response values which are in essence categorical and in a limited way ordinal have been converted into a numerical, interval valuation scale. If the numbers assigned were merely used to keep track of proportions of responses in each category, a conversion to numerical values would be a harmless waste of effort. In virtually every instance in which such forms are used, however, the resulting numerical values are averaged, first across all responses to the same item within a course, and then across all items. In the majority of cases, it is this final average upon which judgements concerning "teaching effectiveness" are based. This computational absurdity is frequently carried one step further: standard deviations are computed again item by item and then across all items. This procedure implies, bizarrely, that the one unit difference between neutrality and agreement has the same meaning as the one unit difference between, say, disagreement and strong disagreement. Surely we can average outrage and indifference and come up with, maybe, irritation, can't we?
As an example of the lengths to which this inane compulsion to drive essentially subjective responses into meaningful quantitative pigeonholes, one might consider the following example taken from student evaluations completed and then administratively evaluated at BHSU. In the case of one faculty member's evaluations from the spring semester of 2000, he received an average score, across all thirteen items of 2.03 as opposed to a departmental average of 1.99, and this difference, or near agreement, of averages was deemed sufficiently significant as to be taken formal notice of in his written performance evaluation. Had one student across all those in all his classes moved responses either one category "up" or one category "down," the difference would either have been eradicated or doubled, respectively. Indeed, a qualitative examination of the pattern of response, course by course, reveals a striking number of instances of the pissed-off-student syndrome: one or two students in a given course, likely indignant at not having received the sort of outcome to which they thought themselves entitled, who go through the entire form and mark each item "5." The effect of this procedure in a course of only fifteen to twenty students on the, as already noted, meaningless but nonetheless important average is dramatic.
The question arises, in view of the foregoing remarks, why do administrators who, on the basis of academic training in the sciences, statistics, and mathematics, really ought to know better persist in assigning value to nonsensical computations based on subjective, and to large degree unreliable, data? A hint at the answer to that question is provided by a more cautious handling of the data gathered from the evaluation forms, an answer which leads us back to the opening paragraph and Professor Trout's essay.
Rather than considering student responses after having been deformed into a misleading numerical scale, we consider them for what they are, categorical responses. In particular, we consider how the proportion of categorical responses in positive categories correlates with the proportions of positive values of another categorical variable of widespread interest in academia, namely assigned letter grade. In the fall semester of 2000 at BHSU, some 9,773 student-evaluation-of-teaching forms of the type described above were completed. We will use this data and particular homogeneous subsets of this data to carry forward our analysis.
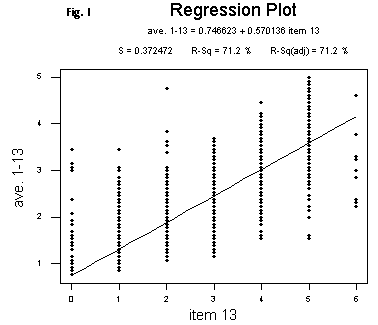
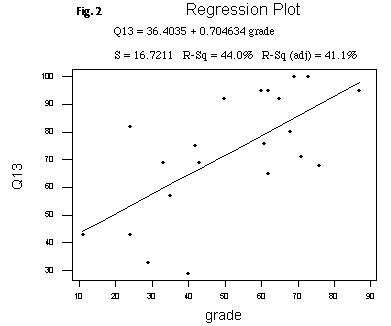
As an initial step in our discussion, we focus our attention on item 13, the final evaluative item, on the form. The statement to which students respond reads, "Overall, this was a good class." Arguably, this is the most vague item presented and the one least susceptible to the application of any objectifying criteria. It is interesting then to note that over all 9,773 submitted forms, the value of the correlation coefficient between the numerical responses to this item and the average of the numerical responses to all of the first thirteen items taken form by form is 0.844, a value which connotes a very high degree of linearity in the relationship between the two. (I have appended the scatterplot [Fig. 1] arising from these two variables taken, again, form by form. As I have argued above, the calculation of averages, either across all responses to a given item or, worse, across all responses to a variety of items, is a misguided computation at best, but if one were to compute such an all-encompassing average, this degree of correlation implies that one might spare oneself a great deal of effort and merely have students respond to item 13. The overall average and the average response to the highly subjective item 13 [Fig. 2] obviously needn't be in close agreement on the basis of the high degree of correlation (though in fact they are; the aggregate average is 1.78, and the average response to item 13 is 1.81). But the degree of correlation indicates that information about one of the two variables is as good as information about the other, and so one might just as well have students provide their impression of the course, the essence of what is asked in item 13, if ultimately the focus of attention is the aggregation of all of their responses in one grand average.
Focusing our attention then on item 13, we might well ask, "What is it about the course, the instructor, or indeed the expectations of students that it is measuring?" Some insight into the answer to that question can be gained by treating item 13 responses as categorical ones and examining the correlation of the proportion of who respond positively to item 13 with the proportion of students receiving letter grades of A or B, course by course. The comparison will be meaningful only if extraneous variables (i.e., inputs other than those under the direct control of the instructor) are controlled for and if there is enough variability in the latter of the aforementioned variables to ensure that there is the possibility of an affect to be measured. Hence, we restrict our attention to different sections of the same course, all of which are taught on a common syllabus and for which the grading standards are widely variable from section to section. Moreover, we select a course with sufficiently many sections so that some confidence can be placed in the correlation coefficient (Pearson's r) as measuring a genuine relationship. For these purposes on the BHSU campus in the fall semester of 2000, the course English 101: Introduction to Written Communication, answers nicely. Some 21 sections were offered in the fall of 2000. The proportion of A's and B's assigned ranged from a low of 11% to a high of 87% with a distribution somewhat normal in character, allowance made for the fact that the data set contains but 21 entries. All sections were taught from the same syllabus and students were given a common final examination; thus, with respect to issues beyond the instructor's control, the courses under consideration represent as homogeneous a group as one might obtain. For these 21 sections the correlation coefficient between percent of positive responses to item 13 and percent of A's and B's given was 0.664, a figure far too close to 1 to be the result of chance. In other words, item 13, and through its high correlation with average response so the entire form, seems to be students' happiness with their grades. Or, put a little more suggestively, the form seems to be measuring consumer satisfaction.
All of this brings us back around to our point of departure. What is the meaningful context for a consideration of student evaluations of teaching, and, an entailed question, why do so many who know or should know better persist in fraudulent quantitative use of these instruments? The data explored above, and I'm sure similar data available at other institutions, point at an answer. Student evaluations of teaching are not intended primarily to improve teaching. They are intended to provide primary evidence of the degree to which our student-consumers are content with what they deem to be our product, their grades. The evidence suggests that they do this admirably. Along the way, of course, they can effectively draw attention to those faculty whose classroom deportment does not conform to this provider/consumer paradigm of higher education while masquerading as an instrument which faculty can use to become more effective teachers. In other words, the student evaluation of teaching is to be viewed as another element facilitating the effective organization of our society's largest preoccupation, consumerism.
Of course, to anyone who has spent a significant amount of time teaching lower division courses, particularly general education courses, this quantification is merely a late confirmation of what one has observed informally. It is common knowledge that those who give higher grades are generally rewarded in an obvious quid pro quo with better teaching evaluations. (On this, as on many campuses, the College of Education therefore consists of nothing but outstanding teachers and equally outstanding students.) The tendency of the underlying mentality of our students is to fit their experience in our classrooms into the larger scheme of consumer transactions which occupy the predominant role in our society. The questions with which they approach the evaluation of teaching are, "Have I been well-served?" and "Was the product I purchased delivered as conveniently as possible?" The product in question, of course, is the degree and, as part of that, the good, or at least tolerable, grades which make the degree possible and perhaps more valuable. The student evaluation of teaching is an opportunity in this scheme for students to register the ease with which the product/service was secured. The "infotainment" criterion which students seem frequently to apply to their subjective evaluation of their classroom experiences, as outlined in Professor Trout's essay, is in some sense just an aspect of this matter of "ease" or "convenience." When I have my oil changed, my burger flipped, my pizza delivered, generally my desires as a consumer placated, I want primarily to have the goods delivered but if possible delivered with a little diversion on the side. It makes the waiting for satisfaction that much more bearable. The quantitative role played by student evaluations of teaching in the transaction is to allow administrators to gauge how effectively faculty members facilitate this transaction in a market of increasingly demanding consumers.
On the back of the sheet provided, please respond to the following questions:
What was the most effective aspect of the class for you?
What might have improved the class for you?
What was your overall evaluation of this class?
Do you have other constructive comments you would like to add?
Using a No. 2 lead pencil, blacken the response category that corresponds to your rating for each item below. Darken each oval completely. Use the following scale for items 1-12:
(1) Strongly Agree (2) Agree (3) Neutral (4) Disagree (5) Strongly Disagree (6) No Opinion/Not Applicable
The course was well organized.
The instructor's presentations were relevant to the course.
The course objectives, requirements, and grading procedures were clearly explained.
The instructor made the subject matter understandable.
The lectures, readings, course work/activities, and assessments worked together to make a coherent course.
I believe my knowledge and understanding of the subject increased as a result of taking this course.
The instructor encouraged and was receptive to student questions and feedback.
The course stimulated thinking in the subject area.
The instructor was available during posted office hours.
Students were kept informed of their progress.
The instructor followed the grading procedures outlined in the syllabus.
The instructor demonstrated an interest in the subject.
Overall, this was a good class.
*************Student Information*************
I am taking this course primarily as a(n):
(1) Major (2) Minor (3) General Education (4) Elective (5) Other
My class rank is:
(1) Freshman (2) Sophomore (3) Junior (4) Senior (5) Other
My current BHSU GPA is:
(1) 4.00 - 3.3 (2) 3.29 - 2.6 (3) 2.59 - 2.00 (4) 1.99 or below (5) not known
I would rate my effort in this class as worthy of a(n):
(1) A (2) B (3) C (4) D (5) F